Transformer技术的崛起:从自然语言处理到跨领域应用的革命
自2017年谷歌研究团队在论文《Attention Is All You Need》中提出Transformer架构以来,人工智能领域经历了一场深刻的变革。这种基于注意力机制的模型最初旨在改进序列到序列的自然语言处理任务,但其影响已远超语言处理,渗透到各个领域。

Transformer的基本原理
Transformer架构的核心在于自注意力机制,它能够在处理输入数据时,动态关注数据中的不同部分。与传统的循环神经网络(RNN)不同,Transformer无需顺序处理数据,这使得它在并行计算方面具有显著优势。这种特性使Transformer在处理大规模数据时表现出色,显著提高了训练效率和模型性能。
在自然语言处理中的应用
Transformer最初被应用于机器翻译任务,但很快证明其在各种自然语言处理任务中都具有卓越的性能。例如,OpenAI开发的GPT系列模型和谷歌的BERT模型,都是基于Transformer架构的语言模型。这些模型在文本生成、问答系统和情感分析等任务中表现出色,推动了自然语言处理技术的飞跃。
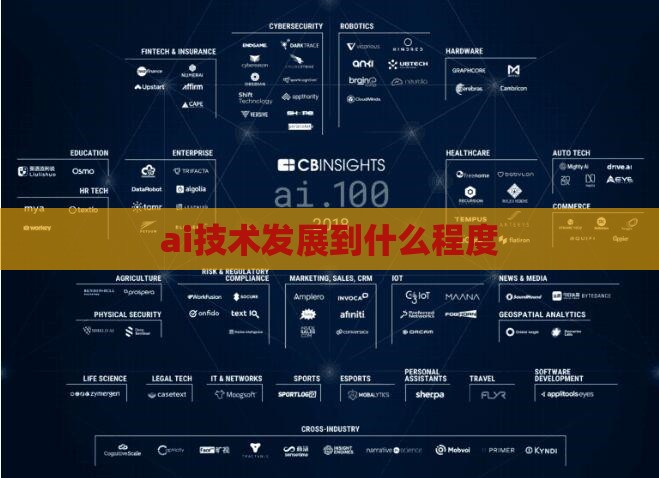
跨领域的应用拓展
随着研究的深入,Transformer的应用范围不断扩大,涵盖了多个领域:
计算机视觉:传统上,卷积神经网络(CNN)是处理图像数据的主力模型。然而,研究人员发现,Transformer在图像分类、目标检测等任务中也能取得优异的成绩。例如,Vision Transformer(ViT)模型将图像分割成小块,作为序列输入模型,取得了与CNN相媲美的效果。
生物信息学:在蛋白质结构预测和基因组分析中,Transformer被用于捕捉生物序列中的复杂模式。例如,AlphaFold模型利用Transformer预测蛋白质的三维结构,解决了生物学领域的长期难题。
自动驾驶:Transformer在处理传感器数据融合和路径规划方面展现出潜力。通过分析车辆周围环境的多模态数据,Transformer模型可以更准确地预测行人和其他车辆的行为,提高自动驾驶的安全性和可靠性。
Transformer的优势与挑战
Transformer的成功归功于其独特的架构设计,但也面临一些挑战:
优势:
并行处理:由于无需顺序处理数据,Transformer能够利用并行计算资源,加速模型训练。
长程依赖捕捉:自注意力机制使模型能够关注输入数据中的任意部分,适合处理具有长程依赖关系的任务。
挑战:
计算资源需求:Transformer模型通常包含大量参数,训练和推理过程需要高性能的计算资源。
数据需求:大型Transformer模型需要大量高质量的数据进行训练,这在某些领域可能难以获得。
未来展望
Transformer架构的出现为人工智能的发展开辟了新的道路。随着研究的深入,我们可以期待Transformer在更多领域实现突破,推动技术进步和应用创新。
版权声明:本文由滑稽实验室网络搜索发布,如有侵权请联系删除。